Python Pandas - DataFrame
数据框是二维数据结构,即数据以行和列的表格形式对齐。
DataFrame的功能
- 潜在的列有不同的类型
- 大小 - 可变
- 标记轴(行和列)
- 可以对行和列执行算术运算
结构 Structure
我们假设我们正在创建一个包含学生数据的数据框。
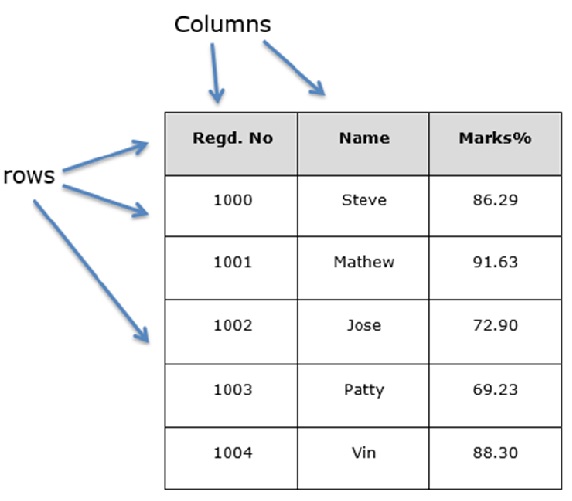
您可以将其视为SQL表或电子表格数据表示。
pandas.DataFrame
可以使用以下构造函数创建pandas DataFrame -
pandas.DataFrame( data, index, columns, dtype, copy)
构造函数的参数如下 -
| S.No | 参数和描述 |
|---|---|
| 1 | data 数据采用各种形式,如ndarray,系列,地图,列表,字典,常量以及另一个DataFrame。 |
| 2 | index 对于行标签,如果没有传递索引,则用于结果帧的索引是Optional Default np.arrange(n)。 |
| 3 | columns 对于列标签,可选的默认语法是 - np.arrange(n)。 仅当没有传递索引时才会出现这种情况。 |
| 4 | dtype 每列的数据类型。 |
| 4 | copy 如果默认值为False,则此命令(或其他任何命令)用于复制数据。 |
创建DataFrame
可以使用各种输入创建pandas DataFrame,例如 -
- Lists
- dict
- Series
- Numpy ndarrays
- 另一个DataFrame
在本章的后续部分中,我们将了解如何使用这些输入创建DataFrame。
创建一个空DataFrame
可以创建的基本DataFrame是空数据帧。
例子 (Example)
#import the pandas library and aliasing as pd
import pandas as pd
df = pd.DataFrame()
print df
其output如下 -
Empty DataFrame
Columns: []
Index: []
从列表中创建DataFrame
可以使用单个列表或列表列表创建DataFrame。
例子1 (Example 1)
import pandas as pd
data = [1,2,3,4,5]
df = pd.DataFrame(data)
print df
其output如下 -
0
0 1
1 2
2 3
3 4
4 5
例子2 (Example 2)
import pandas as pd
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['Name','Age'])
print df
其output如下 -
Name Age
0 Alex 10
1 Bob 12
2 Clarke 13
例子3 (Example 3)
import pandas as pd
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['Name','Age'],dtype=float)
print df
其output如下 -
Name Age
0 Alex 10.0
1 Bob 12.0
2 Clarke 13.0
Note - 观察, dtype参数将Age列的类型更改为浮点。
从ndarrays/Lists的Dict创建一个DataFrame
所有的ndarrays必须具有相同的长度。 如果传递了index,那么索引的长度应该等于数组的长度。
如果没有传递索引,那么默认情况下,index将是range(n),其中n是数组长度。
例子1 (Example 1)
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data)
print df
其output如下 -
Age Name
0 28 Tom
1 34 Jack
2 29 Steve
3 42 Ricky
Note - 观察值0,1,2,3。 它们是使用函数范围(n)分配给每个索引的默认索引。
例子2 (Example 2)
现在让我们使用数组创建一个索引的DataFrame。
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data, index=['rank1','rank2','rank3','rank4'])
print df
其output如下 -
Age Name
rank1 28 Tom
rank2 34 Jack
rank3 29 Steve
rank4 42 Ricky
Note - 观察, index参数为每一行分配一个索引。
从Dicts列表创建一个DataFrame
字典列表可以作为输入数据传递以创建DataFrame。 默认情况下,字典键被视为列名。
例子1 (Example 1)
以下示例显示如何通过传递字典列表来创建DataFrame。
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print df
其output如下 -
a b c
0 1 2 NaN
1 5 10 20.0
Note - 观察,NaN(非数字)附加在缺失区域中。
例子2 (Example 2)
以下示例显示如何通过传递字典列表和行索引来创建DataFrame。
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data, index=['first', 'second'])
print df
其output如下 -
a b c
first 1 2 NaN
second 5 10 20.0
例子3 (Example 3)
以下示例显示如何使用字典列表,行索引和列索引创建DataFrame。
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
#With two column indices, values same as dictionary keys
df1 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b'])
#With two column indices with one index with other name
df2 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b1'])
print df1
print df2
其output如下 -
#df1 output
a b
first 1 2
second 5 10
#df2 output
a b1
first 1 NaN
second 5 NaN
Note - 观察,df2使用除字典键以外的列索引创建DataFrame; 因此,将NaN附加到位。 而df1是使用与字典键相同的列索引创建的,因此附加了NaN。
从Dict of Series创建一个DataFrame
可以传递系列字典以形成DataFrame。 结果索引是传递的所有系列索引的并集。
例子 (Example)
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print df
其output如下 -
one two
a 1.0 1
b 2.0 2
c 3.0 3
d NaN 4
Note - 观察,对于系列1,没有传递标签'd' ,但在结果中,对于d标签,NaN附加了NaN。
现在让我们通过示例了解column selection, addition和deletion 。
列选择
我们将通过从DataFrame中选择一列来理解这一点。
例子 (Example)
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print df ['one']
其output如下 -
a 1.0
b 2.0
c 3.0
d NaN
Name: one, dtype: float64
列添加
我们将通过向现有数据框添加新列来理解这一点。
例子 (Example)
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
# Adding a new column to an existing DataFrame object with column label by passing new series
print ("Adding a new column by passing as Series:")
df['three']=pd.Series([10,20,30],index=['a','b','c'])
print df
print ("Adding a new column using the existing columns in DataFrame:")
df['four']=df['one']+df['three']
print df
其output如下 -
Adding a new column by passing as Series:
one two three
a 1.0 1 10.0
b 2.0 2 20.0
c 3.0 3 30.0
d NaN 4 NaN
Adding a new column using the existing columns in DataFrame:
one two three four
a 1.0 1 10.0 11.0
b 2.0 2 20.0 22.0
c 3.0 3 30.0 33.0
d NaN 4 NaN NaN
列删除
列可以删除或弹出; 让我们举一个例子来了解如何。
例子 (Example)
# Using the previous DataFrame, we will delete a column
# using del function
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']),
'three' : pd.Series([10,20,30], index=['a','b','c'])}
df = pd.DataFrame(d)
print ("Our dataframe is:")
print df
# using del function
print ("Deleting the first column using DEL function:")
del df['one']
print df
# using pop function
print ("Deleting another column using POP function:")
df.pop('two')
print df
其output如下 -
Our dataframe is:
one three two
a 1.0 10.0 1
b 2.0 20.0 2
c 3.0 30.0 3
d NaN NaN 4
Deleting the first column using DEL function:
three two
a 10.0 1
b 20.0 2
c 30.0 3
d NaN 4
Deleting another column using POP function:
three
a 10.0
b 20.0
c 30.0
d NaN
行选择,添加和删除
我们现在将通过示例了解行选择,添加和删除。 让我们从选择的概念开始。
按标签选择
可以通过将行标签传递给loc函数来选择行。import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print df.loc['b']
其output如下 -
one 2.0
two 2.0
Name: b, dtype: float64
结果是一系列标签作为DataFrame的列名。 并且,系列的名称是用于检索它的标签。
按整数位置选择
可以通过将整数位置传递给iloc函数来选择行。
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print df.iloc[2]
其output如下 -
one 3.0
two 3.0
Name: c, dtype: float64
切片行
可以使用':'运算符选择多行。
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print df[2:4]
其output如下 -
one two
c 3.0 3
d NaN 4
添加行
使用append函数向DataFrame添加新行。 此函数将在末尾附加行。
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
df = df.append(df2)
print df
其output如下 -
a b
0 1 2
1 3 4
0 5 6
1 7 8
删除行
使用索引标签从DataFrame中删除或删除行。 如果标签重复,则将删除多行。
如果您观察到,在上面的示例中,标签是重复的。 让我们删除一个标签,看看会丢弃多少行。
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
df = df.append(df2)
# Drop rows with label 0
df = df.drop(0)
print df
其output如下 -
a b
1 3 4
1 7 8
在上面的示例中,删除了两行,因为这两行包含相同的标签0。
